Register now

March 5, 2023
March 28, 2024
%20(1920%20%C3%97%201080px).png)
In this article, we will discuss seven effective strategies to optimize costs for AWS ECS. This discussion is based on the joint webinar between Sedai and AWS, which you can watch here. We will be covering different approaches to managing ECS clusters. In today’s market, the majority of cloud adopters are using container-based infrastructure, such as ECS. While ECS brings together favorable ease of use to containers, it is not without its complexities in managing cost, performance, and availability. Sedai and AWS have come together today to explore different options available to you in managing these complexities.

Sedai has partnered together with AWS from a technical standpoint to deliver tremendous value to AWS customers, utilizing ECS, EKS, or Lambda to autonomously manage their resource allocation through an application lens for improved performance, decreased cost, and heightened availability, all in one platform. Our joint customers together are seeing as high as 50% reductions in cloud cost, 70% increases in performance, and as high as 6X productivity gains from their SRE and DevOps teams.

Amazon Elastic Container Service (ECS) offers a powerful solution for orchestrating containerized tasks and services. To grasp its core concepts and functionalities, let's delve into the fundamental components that make up ECS.
Clusters play a pivotal role in ECS. Essentially, a cluster serves as a logical grouping mechanism for tasks, services, and container instances. In the context of ECS, a cluster can represent a collection of tasks or services utilizing the EC2 launch type, or it can also denote a logical grouping of capacity providers if you leverage them. By default, ECS creates a cluster for you upon initial use, but you have the flexibility to create multiple clusters within your account to maintain resource segregation effectively.
Container instances are crucial building blocks within ECS. These instances refer to EC2 instances that run the ECS container agent and have been successfully registered with a specific ECS cluster. When you execute tasks using the EC2 launch type or leverage an Auto Scaling group capacity provider, ECS strategically places your tasks onto active container instances, ensuring seamless execution within your environment.
Tasks and task definitions form the core entities within ECS. A task represents the live instantiation of a specific task definition, running either on a container instance or within the broader AWS ecosystem. Task definitions, on the other hand, serve as blueprints for your tasks, encompassing essential details such as task names, revisions, container definitions, volume information, and more. They act as comprehensive guidelines for ECS to understand the precise configuration and requirements of your tasks.
Lastly, ECS services empower you to maintain and manage a predetermined number of task instances based on your task definition. By utilizing ECS services, you can ensure a specified number of instances are consistently running within your ECS cluster. Should any task encounter failure, the ECS service scheduler promptly launches a replacement task, guaranteeing the desired number of tasks is maintained for the service at all times.
Talking about the importance of optimization, engineers and engineering leaders have different goals. Sometimes, they have multiple goals. Sometimes, they have one direction that they go in. Sometimes, it's improving the customer's experience. How can you make things faster? Sometimes it's reducing costs. Sometimes, it's a balance of both. In this article, we'll go on talking about cost optimization, but we will try to keep a balance on how we can keep performance intact as well.
This is a case study Sedai did across companies that are using ECS. This specific company is a security SaaS company, which is public.

For every $100 million in revenue, approximately 8.6% was the cloud spent and it’s a very huge amount.
And if we could save 20% to 30% of that 8.6%, which means, on an average, if you can bring down the cloud costs to 6% of your revenue, we saw that the company's bottom-line revenue, bottom-line profit, grew a staggering 17%.
Just by optimizing your cloud cost to 20%, you could see your profitability going up by 70%. That's where cloud cost and performance optimization are critical.
Talking about the over-provisioning, and under-provisioning problem to start with.
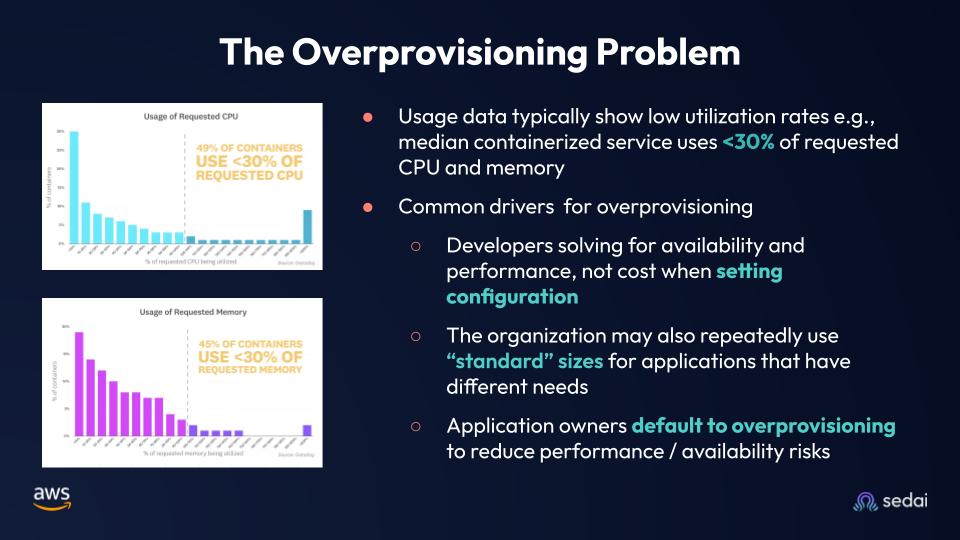
Datadog conducted a study among all their customers who use containers, managing billions of them. What they discovered was that nearly 50% of the containers utilize less than 30% of CPU and memory, indicating a waste of 70%. Why does this occur? Typically, engineering teams prioritize safety and availability, resulting in the inclusion of a buffer. They prioritize solving for availability first, which leads them to allocate extra CPU and memory. Occasionally, they also create additional replicas, contributing to this significant inefficiency. Another reason was, that companies sometimes have hundreds, thousands of services. It's very hard to right-size every service. There are buckets of computing profiles. That is a compute profile of 4 CPU 8 GB that's used across 100 services. There's another compute profile of 2 CPU 32 GB memory that's used across another 50 services. These two were the two common reasons, being safe, and on the other side, having common buckets of compute profiles created this over-provisioning, under-provisioning problem.
Anuj Sharma, Container Solution Architect at AWS, and Benji Thomas, President and COO at Sedai went through 7 Strategies to Effectively Optimize ECS specifically, even though some of these practices can be applied across container environments.
The first strategy is to eliminate over-provisioning and under-provisioning. To save costs, you might have to adjust your provisioning. You don't want to under-provision because that will hit your availability. The first strategy is to safely right-size your service by eliminating over-provisioning and under-provisioning.
To do that exercise, as an engineer, what is the set goal?

(Refer to the image above) On one side is availability. Meet your application demands.
You have typical traffic, max traffic, seasonalities, and unexpected spikes. As a performance engineer, or a software engineer, or an SRE, manage your application demands, not just today but also for the future.
On the other hand, wearing the dollar hat, you might want to save costs. You don't want to waste a lot of resources. That's the balance that you need to manage when you right-size a service, which includes a task as well.
When you do a thorough analysis through your load test and your profiles, you could right-size your service at the same time, you can also discover hidden opportunities where you increase performance as well.
Some of the challenges in right-sizing your services, especially when you're dealing with many services, is that each service is released in today's microservice as well as services are being released very often. Each service has its own vertical and horizontal profile.

Vertical profile is the memory CPU at the task level and the container level if you have a multi-container task. The horizontal profile is the number of tasks that you're running. That's one of the challenges that you need to solve.
Number two, you have your goal. Do you want to optimize for cost? Do you want to keep the cost the same? Do I improve performance? Also, I need to make sure all my seasonality is managed.
The approach to solve this is to right-size your service based on your seasonal needs and production behavior.
At the end of the day, if you do that for each of your services, you can run your workload in the most efficient way.
(Refer to the image above.) An example that you see is a memory-intensive application.
Due to the bucketing of standard compute profiles, initially, the service was at 4 vCPU 8 GB memory and needed 12 tasks, which the monthly cost was around $1,800 per month.
Once you've profiled it right, you understand that it's a memory-intensive application. You are able to bump up memory. You didn't need a lot of CPU, and you didn't need a lot of replicas. That way, you will be able to reduce your cost by more than 30% in this case. Sometimes you will get hidden opportunities where you will save performance as well.
After optimizing your service and task we move forward to the second strategy. This strategy is specifically focused on how you can optimize your EC2-backed cluster.

In the example that we discussed before, if we were to run 10 ports, and the application was a memory-intensive application, in serving a typical traffic that you have, and if you were to run 10 ports, and to serve that traffic, you were expected to run 10 ports, but in actuality, since it was a memory-intensive application, if you had a higher memory profile, you truly didn't have to run those many tasks or ports. What you need is a lesser number of tasks but with a higher memory profile.
Once you do that, you don't need to run the same number of container instances or the same number of the type of container instance. You could choose a container instance with a higher memory profile, and you could run a lesser number of container instances. That way, you save cost.
At the same time, by making that choice to pick a different profile, you have optimized your performance as well. Again, it's a win-win situation.
On the other hand, sometimes you could choose if you want to keep your costs or you want to increase performance. In that case, you might give it more power, adding more CPU, or adding more memory.
For that strategy, the key challenge is to first go back to strategy one. Optimize your service. Identify the right profile of your container instance, and then use that. Resize and rebalance your cluster that way you save on cost and performance.
We already discussed optimizing your service, optimizing the cluster, and the container instances that it runs on. Are we ready for the seasonal spikes? Are we ready for the complex traffic patterns that are coming through? That's where service and cluster autoscalers are important. We have seen this practice where companies provision for the peak traffic that they get. For example, September comes in, and you're already ready for Thanksgiving. You've put in the maximum capacity that you need, which is a cost burden for you. That's not the ideal solution. You would want to keep your scale at the desired state, and you want to be ready for your seasonality patterns, your weekend-- a retail company may have a Monday-afternoon spike.
A tax firm may have a different type of spike. To manage a seasonality, we want to put the right autoscalers in place. You want to put your service auto scalers and your cluster auto scalers. There are a few things that we need to watch for when you put autoscalers. You don't want your autoscalers to behave badly. You need to make sure that you warm up your service continuously but not extensively. Also, when you're scaling, when you reduce your number of tasks, you want to do that concept conservatively and safely.
One example I've seen is, an application that may take a startup CPU spike. If you don't put the right warm-up time frame. For example, have a 10-second warm-up time frame and your application takes more than 10 seconds to warm up, you're going to get the cycle of autoscaling happening. You always want to put the right warm-up values and right cool-down values in your scale-out and scale-in profiles.

We talked about right-sizing your services, right-sizing your clusters, and putting the right autoscalers in place. Comparing our before-and-after values, if you always plan for your peak traffic, you're always putting in the maximum that you need, you end up spending more. But if you put the right autoscalers in place, you have a desired count, which covers most of your scenarios, and then you have a maximum, and then you have scaling in place to get to your max and scale down to your minimum when it's not required.
Enabling telemetry doesn't sound like a strategy, it sounds like a best practice. We wanted to call it out as a strategy because we have seen occasions where companies are not doing this extensively.
Many times, companies only watch CPU and memory, and then they make decisions based on that. What happens is that performance is affected. Sometimes, the other specs go up.
We wanted to call this strategy out to observe, observe, observe your applications, your metrics, your events, your logs, and your telemetry. When you make these optimization choices, make sure you've verified all these for not just your saturation, but you've also verified your performance metrics, which are your traffic and latency events, and also how your dependencies behave using tracers.
Amazon AWS announced Service Connect last year. A lot of this comes in a packed, feature-rich by default with Service Connect. Your discovery, how you connect between services, and even performance metrics are available by default in Service Connect.
When you apply that strategy, the before-and-after picture is typically like this. So you have a before-and-after, which we talked about in the previous slides.
But if you're not observing, you don't know your performance. You're making decisions in the vacuum. But if you know your performance metrics, if you know your dependencies, if you know your events, then you compare everything, and you're confident that the decisions that you have made are good and it works for your bottom line.
Before we dive deep into the strategy, let's talk about the four different purchasing options available for EC2.

Spot instances are placed as one of the four purchasing options available to customers when you are using EC2, which you are probably familiar with at this point of time.
The standard on-demand pay-as-you-go by the second is best for fluctuating workloads from a cost-optimization perspective.
Reserved instances and savings plan, where you commit your usage in a more-or-less flexible way in exchange for significant discounts. It's perfect for steady usage, per se.
And finally, spot instances, which constitute spare capacity in EC2 or Fargate, are available at very steep discounts for up to around 90% of on-demand prices. These are best suited for stateless or fault-tolerant workloads, and we will see why as we go on.

As you all know, when you run your easiest task, either in an EC2 instance, where you as a customer have the full control over the operating system where your easiest task will be scheduled. Or you can choose to run your ECS task in Fargate mode, where AWS relieves you from the operational burden of managing and patching the underlying operating system and managing them for you.
In both of these options, you have the option to apply a spot-pricing model.
You get the obvious benefits of price in exchange for a two-minutes warning for reclaiming but EC2 spot specifically lets you choose the instance pool whereas in Fargate spot you get a diversification automatically.

Any of these purchase options that we just went through rely on the exact same underlying EC2 infrastructure, available across AWS region. There is no difference in the behavior of these instances. Spot is no exception. Spot instances are just idle capacity that is not being used to fulfill the on-demand request, and they are made at cheap prices.
Very important to note here, although the price of spot instances changes in time, it is in no way determined by the highest bid anymore. Bidding is altogether a thing or a concept in the past for spot. Instead, the price calculation now is based on the long-term demand and supply trends for the instances.
Finally, there is only one difference between on-demand and spot instances. The word "spare" implies something, of course, which is that when EC2 instances need the capacity back, spot instances can be interrupted, with the instance receiving a notice that termination will happen two minutes after the fact. This is why spot instances with fault-tolerant or stateless workload are better, where an interrupted instance is replaceable with spot capacity when available with little or no impact to your workload.

Speaking of capacity, it is divided into what we call spot instance pools. Each of these audience inquiries that you see represent a spot instance pool.
Each one is a combination of specific instance type, size, availability, zone, and region. This really adds up to a lot of pools.
The price and capacity of these pools fluctuates independently from each other. If you use the same instance type on three different availability zones, you are effectively consuming capacity from three different spot pools.
Tying this back to the spot interruption, it is easy to see that the more instance pools you use, the more diverse you are, which means that you decrease the chances of a large portion of your sport instance being interrupted if demand increases. It's just like how the saying “Don't put all your eggs in one basket” goes.

At this stage in the lifetime of spot, with bidding completely gone, and all the new capabilities we have, the data shows us that the interruptions have become fairly infrequent, with only 5% of spot instances that have been interrupted in the last three months or so. The more customers adopt the best practices and properly diversify, the better spot as a whole will function.

As a good strategy, it's best to add a mix of on-demand instances and spot instances. Even if you end up over-provisioning, let's say, by 50%, just by introducing one third of spot and remaining on-demand, you are likely getting around 5% to 10% of saving in cost.

Now, let's cover how to implement spot interrupt handling in ECS as a service. Let's see how that works in this area. The good news is, this can be automated just by setting one parameter, which is ECS Enable Spot Instance Draining to True for the ECS Container Agent on EC2 instance via user data during the instance creation time. This effectively drains the instances from ECS control plane and stops all the pending tasks that are scheduled on that instance.
ECS does this by setting all the tasks running on that instances to draining by sending a SIGTERM signal, let's say, at T0, and a SIGKILL signal 30 seconds after. This lets you stop your application gracefully, or even do the last mile log collection.
ECS will also deregister all the tasks from the load balancer target group. And then ECS will try to reschedule the task on the remaining instances that you have available.
Therefore, if I have to summarize this strategy, the implementation should consider architectural choices such as dynamically including a mix of on-demand and spot instances, optimal multi-year commitment designed to recover from interruptions. And most importantly, consider the profile of your workloads, and see what kind of purchasing option can it fit in.

As a sample calculation, just by introducing a mix of on-demand, spot, reserved instance, or using savings plans, you are looking forward to roughly around 50% reduction in the overall cost.

Tagging EC2 instances and your task enables you to get a full visibility on the cost. Each tag is a simple label consisting of a key and an optional value to store information about the resource or the data written in that resource. Tagging addresses a variety of use cases, whether it be cost and finance management, operations or support, or even data management or access controls, per se.
For today's discussion, however, we will on focus tagging for the cost and finance management use cases only. Cost allocation refers to the assignment or distribution of the incurred cost to the users or the beneficiaries of those costs following a defined process. We divide the cost allocation into two types, showbacks and chargebacks. Showback tools and mechanisms help increase the cost awareness, whereas chargeback helps with the cost recovery and drives enablement of cost development.
Showback is about presentation, calculation, and reporting the charges incurred by a specific entity, let it be an EC2 instance or a specific task on ECS, such as business unit application, user, or cost center. It is important to devise a tagging strategy that addresses all your organizational needs, not only limit it to cost and finance management.
Overall, your tags could be a combination of region, and environment, let it be dev environment, test environment, so forth. Application tiers such as middle-tier, front-end, database-tier, or a specific unique identifier for that application, depending on how your organization is structured, and the overall objectives that you want to fulfill with tagging.
Tag enforcement could be either reactive or proactive, depending on the migration and the modernization journey that you are currently going through, and depending on which phase you are in this journey. Consider using tools such as tag policies, or service control policies, or IAM policies, et cetera, to enforce proactive tagging.
And implementing these typically have a tendency to break your existing automation for the workloads. Whereas reactive tagging, such as tag editors, or AWS config rules, or custom Lambda functions, typically do not break your existing automation.
Proactive:
Reactive
A combination of both of these worlds in terms of proactive and reactive tagging is considered best for effective tag management.

The benefit of cloud comes specifically from the costing standpoint. It is best realized when you use the resources when you need it, and if you don't need it, don't use the resources. This effectively ensures that you are optimizing your OpEx versus comparing it to a traditional model of high CapEx, per se.
You may have a dev environment that you don't use over the weekends, or in the night time, per se. Consider shutting them down if you don't need it. AWS provides solutions such as AWS instance scheduler, which automates the starting and stopping of EC2 instances.
As an example, if you just consider shutting down your environment or your dev environment, per se, which you may not use it over the night or over the weekend, it will result you approximately a cost saving of around 29% If you operate just 24-cross-five, just five days in a week, when you compare it against running 24-cross-seven. So that by itself is giving you around 29% benefit in cost.
We have talked about all these strategies- how you could optimize for cost and performance, optimizing your services, clusters, doing your telemetry right, targeting well, using purchasing options wisely and using schedulers.
The challenge now is, how best can you implement it? You could do it all manually. You could write your automation. And there are multiple levels of automation. You could write automation that is, again, manually triggered. You could write automations that are automatically triggered but without any feedback loop. Or you could be autonomous where you have automation. There's a feedback loop coming in. You learn from it. You understand the efficacy. And then you improve on your actions in the next phase.

To give a recap, we went through multiple strategies and different controls and levers that you could adjust to optimize your services. These are things that are in your control.
As engineers managing the cloud, there are things that are not in your control which are the traffic, seasonality patterns, and the releases that happen. There are inputs and there are knobs that we could manage and this defines the complexity of how you could optimize, and how you could apply all those learnings that we talked about.
So let me take an example of a company with 100 microservices.

Average release is one time per week. Each of these microservices, at least once per week, and there are different performance metrics to be analyzed each time it is released. And there are different seasonality patterns for the service. Even within a company with a specific seasonality, there'll be a group of microservices that follows a different seasonality. A retail company doesn't mean all the microservices follow the standard online purchase model. There are applications with different seasonalities. It's important to analyze the traffic seasonality and how they behave when we optimize them
Look at the staggering number of combinations of knobs that you could adjust in the scenario.
That's where a higher level of automation or autonomous actions are more important. You don't want to just write random automation and leave it in there. You want to put all these things in practice, but you want to make sure that there are knobs in place to learn and improve on that.
The ideal scenario is you have high-level goals.

What do you want to achieve for a group of applications? You have tagged your applications well. For a group of applications, do you want to hit a cost-duration balance?
Do you want to improve performance? Do you want to decrease cost? That should be the goals that we operate on.
On the other hand, if you're managing with templates per service, you end up with hundreds of templates that need to be modified every release. For individual services and tens of services, plus your auto scalers and your service autoscalers.
Ideally, you don't want to shift left your production runtime responsibilities. You want to shift it up where you have an autonomous system in place, where it optimizes your runtime parameters. You still need your templates for your software versions, your dependencies, and all those things. But shift up is the right strategy to manage your runtime parameters.

The actual validation of your actions and how it behaves can be missed. You can enhance the automation to do that. But automation becomes autonomous when you do all five of these.

If you were to do this by yourself, typically, you have a fleet. You have multiple services. They're all being observed well. That means the telemetry is perfect. Ideally, you want to build an autonomous platform where your topology is being discovered frequently. You're watching your metrics 24/7. Every time you're identifying your app behavior based on the releases, you safely reconfigure them, and optimize them.
You identify what happened and validate the efficacy of the action. You learn from it and then keep repeating the loop. That's how a typical autonomous system works.
.png)
.svg)
.svg)






