Optimizing AWS DevOps cost and efficiency requires controlling how pipelines, environments, and scaling policies behave after every change. Most waste builds quietly through unbounded CI concurrency, oversized build infrastructure, idle environments, and autoscaling rules that never get revisited. Small misconfigurations compound quickly at AWS scale, turning temporary fixes into permanent cost drift. By choosing the right AWS DevOps tools and applying clear lifecycle controls, you can tie cost directly to deploys, pipelines, and runtime behavior.
AWS environments rarely become expensive overnight. Costs build up through CI pipelines that never scale down, lingering preview environments, and autoscaling that overreacts after traffic spikes.
Underutilized EC2 instances, inflated EKS requests, and oversized build jobs turn routine DevOps work into ongoing cost pressure.
Industry data shows that structured cloud optimization programs cut cloud spend by 25–30% within 12 months, revealing the extent of inefficiency in daily operations.
That’s why AWS DevOps optimization matters. In this blog, you’ll explore 30 AWS tools and 10 practical strategies to control spend, improve efficiency, and keep systems reliable as they continue to change.
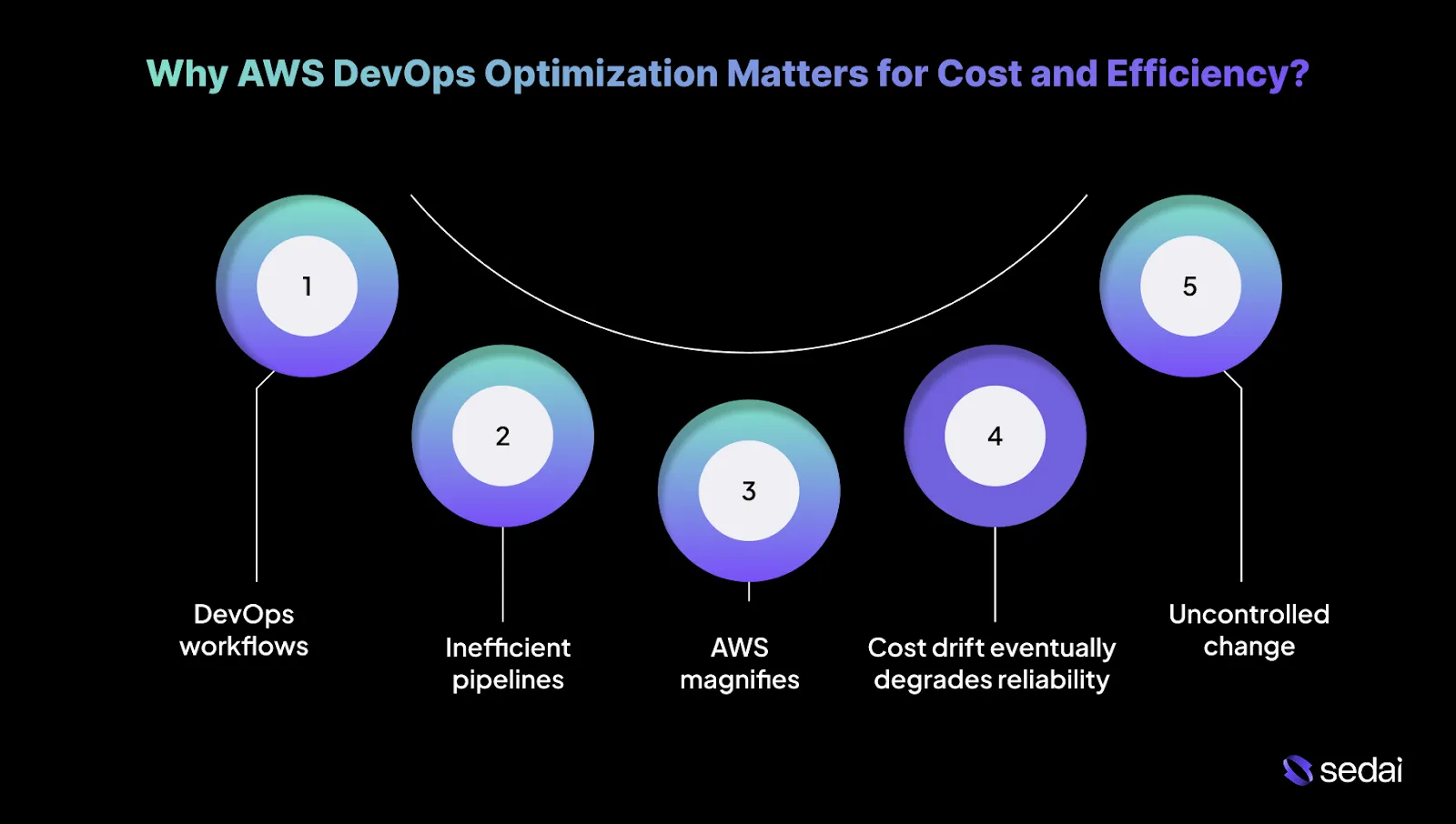
Why AWS DevOps Optimization Matters for Cost and Efficiency?
AWS DevOps costs rarely come from a single service running hot. They accumulate through CI pipelines without clear limits, environments that never shut down, and autoscaling policies that overcorrect under load.
AWS DevOps optimization focuses on controlling how infrastructure responds to change so cost stays predictable. Here’s why it matters for cost and efficiency:
1.DevOps workflows quietly drive most AWS waste
Auto-scaling pipelines, oversized builds, inflated EKS requests, and long-lived preview environments scale up but rarely scale back. DevOps optimization adds lifecycle awareness so infrastructure responds to real demand and baseline costs do not grow with every deploy.
2.Inefficient pipelines increase both cost and delivery time
Slow CI consumes more compute and stretches feedback loops, pushing teams toward retries and excess parallelism. Optimized workflows use caching, concurrency limits, and right-sized runners to cut CI spend and shorten lead time.
3.AWS magnifies small DevOps mistakes at scale
Unbounded autoscaling, verbose logging, and aggressive retries multiply quickly at scale. Guardrails ensure growth follows workload signals, not temporary misconfigurations.
4.Cost drift eventually degrades reliability
Post-incident capacity increases are rarely rolled back and often mask system issues. Optimization makes changes auditable, validated, and reversible.
5.Uncontrolled change makes the cost unpredictable
Without controls, each deploy alters infrastructure behavior and surfaces only in monthly bills. Tying cost to deployments exposes inefficiencies early, before they harden into the system.
Once the benefits of AWS DevOps optimization are clear, it becomes easier to evaluate the tools that can deliver those results.
Suggested Read: AWS Savings Plans Vs Reserved Instances in K8s: Key Differences
Choosing an AWS DevOps optimization tool is all about how effectively it fits into real engineering workflows. Many tools surface cost data but fail to connect it to deployments, scaling decisions, or pipeline behavior.
The right tool makes cost impact visible at the same points where systems are designed, deployed, and scaled. Here’s what to consider when you’re selecting AWS DevOps optimization tools:
1.Recommendations must include operational risk
Tools that only recommend downsizing without showing reliability impact introduce production risk. Teams need visibility into how a change affects latency, error rates, saturation, and rollback behavior.
Optimization is only effective when cost reductions are evaluated alongside system safety.
2.The tool must fit existing DevOps workflows
If a tool operates outside CI/CD, IaC, and observability systems, it is unlikely to be adopted. You expect integrations with tools and deployment pipelines. Optimization sticks only when it lives where engineers already make changes.
3.It must expose misuse patterns
Most cost waste comes from repeated misuse, such as unbounded CI concurrency and idle EKS capacity. A strong tool surfaces these patterns early and shows how they develop over time. This helps teams address root causes.
Once you know what to consider in a tool, it helps to see the key AWS options available for DevOps optimization.
AWS tools for DevOps optimization provide granular control over cost, performance, and scaling across CI/CD pipelines, compute resources, and container workloads.
They enable you to enforce lifecycle policies, monitor real-time usage, and automate right-sizing to prevent inefficiency before it impacts production or budgets. Below are the key AWS tools for DevOps optimization.
1.Sedai
Sedai is an autonomous cloud optimization platform that continuously enhances AWS workload cost, performance, and reliability by taking direct action on infrastructure and configuration.
Sedai closes the loop between detection and execution, operating continuously after deployment without waiting for human intervention.
Sedai integrates with AWS services such as EC2, EKS, ECS, Fargate, Lambda, RDS, Auto Scaling Groups, and EBS. It builds behavior models from real workload telemetry to understand application performance under varying traffic and resource conditions, then applies safe, incremental optimizations in production.
Sedai does not modify application code or replace CI/CD, IaC, or observability tools. It works alongside them, focusing on runtime optimization once workloads are live.
Key Features:
- Workload behavior modeling: Learns normal performance and resource usage patterns for AWS services over time, distinguishing expected variability from genuine performance risk.
- Application-aware optimization: Evaluates service dependencies and downstream impact before making changes across distributed AWS architectures.
- Autonomous infrastructure actions: Continuously rightsizes compute, adjusts capacity, and tunes configurations without manual intervention or scheduled tasks.
- Safety-first execution: Applies changes gradually using learned baselines, guardrails, and rollback controls to avoid disruption.
- Continuous cost optimization: Reduces overprovisioning through real-time rightsizing rather than static recommendations or periodic reviews.
- Proactive performance protection: Detects emerging anomalies early and resolves them before they escalate into user-visible incidents.
Best For: Engineering teams running large, dynamic AWS environments that need continuous, autonomous optimization of cost and performance without increasing operational burden or requiring manual tuning.
If you’re looking to optimize your AWS DevOps costs with Sedai, use our ROI calculator to estimate your potential savings by automating resource optimizations, rightsizing, and reducing inefficiencies across your AWS infrastructure.
2.AWS CodePipeline
Source
AWS CodePipeline is a managed CI/CD orchestration service that coordinates source, build, test, and deployment stages across AWS and external tools.
It acts as the pipeline controller, managing stage transitions, approvals, and execution order without performing the build or deployment itself.
Key Features:
- Event-based pipeline triggers: Automatically starts pipelines from source changes or upstream actions.
- Service-level orchestration: Natively coordinates CodeBuild, CodeDeploy, CloudFormation, Lambda, and third-party tools.
- Controlled release flow: Supports manual approvals and conditional stage transitions.
- Infrastructure-defined pipelines: Pipelines can be versioned and deployed using CloudFormation or CDK.
Best For: Teams managing multi-stage AWS delivery workflows that require consistent, auditable release orchestration.
3.AWS CodeBuild
Source
AWS CodeBuild is a fully managed build service that executes compilation, testing, and packaging inside ephemeral container environments. It removes the need to provision or manage build servers while scaling build capacity per job.
Key Features:
- Ephemeral container builds: Each build runs in an isolated container environment.
- Source-controlled build logic: Build steps are defined using buildspec.yml files.
- IAM-scoped execution: Build jobs assume IAM roles with least-privilege access.
- Dependency caching support: Local and S3 caching reduce repeated dependency downloads.
Best For: Teams that need scalable, isolated build execution tightly integrated into AWS-native CI pipelines.
4.AWS CodeDeploy
Source
AWS CodeDeploy automates application deployments to EC2, ECS, Lambda, and on-premises compute with controlled rollout behavior. It focuses on deployment safety by managing traffic shifting, health validation, and automated rollback.
Key Features:
- Deployment strategy management: Supports in-place and blue/green deployment models.
- Health-driven rollback: Automatically reverts deployments based on alarms or failed checks.
- Lifecycle hook execution: Runs validation scripts at defined deployment phases.
- Service-native traffic shifting: Uses load balancers and Lambda aliases for controlled cutovers.
Best For: Teams releasing frequently to production that need predictable rollouts with automated failure handling.
5.AWS CodeCommit
Source
AWS CodeCommit is a managed Git repository service hosted entirely within AWS. It provides source control tightly integrated with AWS IAM and auditing mechanisms.
Key Features:
- Standard Git compatibility: Works with existing Git tooling and workflows.
- IAM-based authentication: Repository access is controlled using IAM policies.
- Encrypted data storage: Source code is encrypted at rest and in transit by default.
- CI/CD pipeline integration: Repository events can trigger CodePipeline executions.
Best For: Organizations requiring AWS-native source control with centralized identity and audit controls.
6.AWS CodeCatalyst
Source
AWS CodeCatalyst is an integrated DevOps service that combines repositories, CI/CD workflows, issue tracking, and environments into a single AWS-managed workspace.
It reduces operational overhead by standardizing common DevOps workflows for AWS-centric teams.
Key Features:
- Unified DevOps interface: Centralizes repositories, pipelines, and project tracking.
- Prebuilt CI/CD workflows: Provides opinionated pipelines optimized for AWS services.
- Workspace-level access control: Uses AWS identity integration for project permissions.
- Direct environment connectivity: Deploys directly into linked AWS accounts.
Best For: Teams seeking rapid DevOps standardization without assembling multiple discrete AWS services.
7.AWS CloudFormation
Source
AWS CloudFormation provisions and manages AWS infrastructure using declarative templates. It enforces a consistent infrastructure state through dependency management and transactional updates.
Key Features:
- Declarative infrastructure templates: Resources are defined and version-controlled as code.
- Dependency-aware execution: Automatically orders resource creation and updates.
- Configuration drift detection: Identifies deviations from declared infrastructure state.
- Transactional rollback behavior: Reverts changes automatically on failed updates.
Best For: Teams operating regulated or large-scale AWS environments that require deterministic infrastructure changes.
8.AWS Cloud Development Kit (CDK)
Source
AWS CDK enables infrastructure definition using general-purpose programming languages. It introduces higher-level abstractions while still deploying through CloudFormation.
Key Features:
- Programmatic infrastructure definition: Uses languages like TypeScript, Python, and Java.
- Reusable construct abstraction: Encapsulates architectural best practices into constructs.
- CloudFormation synthesis: Converts code into deployable CloudFormation templates.
- Application-aligned infrastructure: Enables infrastructure logic to evolve with application code.
Best For: Senior engineers who prefer code-driven infrastructure with reusable architectural patterns.
9.AWS CloudWatch
Source
AWS CloudWatch collects and stores metrics, logs, and events for AWS resources and applications. It serves as the foundational telemetry layer for operational monitoring and alerting.
Key Features:
- Service-native metrics: Automatically collects metrics from AWS services.
- Centralized log ingestion: Aggregates logs for querying using Logs Insights.
- Alarm-based alerting: Triggers actions based on metric thresholds or anomalies.
- Custom metric support: Enables application-level observability signals.
Best For: Teams responsible for operating and monitoring production AWS workloads.
10.AWS CloudTrail
Source
AWS CloudTrail records AWS API activity across accounts and regions. It provides authoritative visibility into who changed what, when, and from where.
Key Features:
- Comprehensive API event logging: Captures management and data events.
- Security alert integration: Streams events to CloudWatch for detection workflows.
- Organization-wide visibility: Centralizes activity logs across multiple accounts.
- Compliance-grade audit trails: Maintain immutable records for investigations.
Best For: Organizations requiring strong governance, auditability, and security traceability.
11.AWS Lambda
Source
AWS Lambda executes event-driven code without requiring server management. It is commonly used to automate DevOps workflows and infrastructure operations.
Key Features:
- Serverless execution model: Eliminates capacity planning and host management.
- Native event integrations: Responds to events from AWS services and schedules.
- Per-function security isolation: Uses dedicated IAM roles for execution control.
- Operational automation support: Enables deployment hooks, remediation tasks, and glue logic.
Best For: Teams implementing event-driven automation and lightweight operational workflows in AWS.
12.AWS Fargate
Source
AWS Fargate is a serverless compute engine that runs containers without exposing or managing underlying EC2 instances. It moves container operations from node-level management to task-level execution and isolation.
Key Features:
- No node management: Eliminates responsibility for provisioning, patching, or scaling worker nodes.
- Task-level resource allocation: CPU and memory are defined per task or pod.
- Orchestrator integration: Works with both ECS and EKS scheduling models.
- Usage-based billing: Charges only for CPU and memory while containers are running.
Best For: Teams that want to run containers without managing or scaling container infrastructure.
13.Amazon ECS
Source
Amazon ECS is a fully managed container orchestration service designed for AWS environments. It emphasizes operational simplicity and deep AWS integration.
Key Features:
- AWS-managed control plane: Removes the need to operate orchestration infrastructure.
- Multiple launch types: Supports EC2-backed clusters and Fargate-based execution.
- Service-level scheduling: Handles container placement, restarts, and scaling automatically.
- Tight AWS integration: Natively integrates with IAM, ALB, Auto Scaling, and CloudWatch.
Best For: Teams running containerized workloads that prefer AWS-native orchestration with minimal operational overhead.
14.Amazon EKS
Source
Amazon EKS is a managed Kubernetes service running upstream Kubernetes with AWS-managed control plane components. It lets teams standardize on Kubernetes while offloading cluster availability and upgrades.
Key Features:
- Managed Kubernetes control plane: AWS operates etcd, API servers, and control plane availability.
- Flexible compute backends: Supports EC2 nodes, managed node groups, and Fargate.
- IAM and RBAC integration: Maps AWS IAM identities to Kubernetes access controls.
- Upstream compatibility: Works with standard Kubernetes tooling and operators.
Best For: Teams standardizing on Kubernetes that want AWS-managed reliability without vendor-specific modifications.
15.Amazon EventBridge
Source
Amazon EventBridge is a managed event bus that routes events between AWS services, custom applications, and SaaS platforms. It enables event-driven architectures by decoupling event producers from consumers.
Key Features:
- Centralized event routing: Routes events across accounts, regions, and services.
- Pattern-based filtering: Triggers targets only when event rules match.
- Schema discovery support: Automatically identifies and documents event structures.
- Automation enablement: Drives operational workflows and automated responses.
Best For: Teams building loosely coupled systems or event-driven DevOps automation.
16.AWS Device Farm
Source
AWS Device Farm provides automated testing on real mobile devices hosted in AWS-managed labs. It removes the need to maintain physical device infrastructure.
Key Features:
- Parallel execution capability: Executes multiple test suites concurrently to reduce feedback time.
- CI/CD integration: Fits seamlessly into automated testing pipelines.
- Physical device testing: Runs tests on real phones and tablets.
- Rich test artifacts: Produces logs, screenshots, and video recordings.
Best For: Teams validating mobile or web applications across devices as part of CI/CD pipelines.
Terraform is an infrastructure-as-code tool that provisions and manages resources using a declarative configuration model. It ensures predictable infrastructure changes via state-based execution.
Key Features:
- Declarative configuration language: Infrastructure is defined as versioned code.
- Provider-based extensibility: Supports AWS and other cloud platforms.
- State-driven execution: Calculates changes by comparing the desired and actual state.
- Plan-before-apply workflow: Shows exact infrastructure changes before execution.
Best For: Teams managing infrastructure across multiple environments or cloud providers.
Spacelift is an orchestration and governance layer for IaC execution. It controls how and when changes are planned and applied.
Key Features:
- Centralized IaC orchestration: Manages plans and applies across environments.
- Policy-based guardrails: Enforces approvals, access rules, and deployment policies.
- Multi-tool support: Works with Terraform, OpenTofu, and CloudFormation.
- Audit-ready logs: Captures detailed execution history and metadata.
Best For: Teams scaling IaC usage that need governance, visibility, and controlled execution.
19.GitLab CI/CD
Source
GitLab CI/CD provides integrated pipeline automation within GitLab repositories. It unifies source control, pipelines, and DevOps workflows in a single platform.
Key Features:
- Pipeline-as-code: Pipelines defined with versioned YAML files.
- Runner-based execution: Jobs run on shared or self-hosted runners.
- End-to-end DevOps integration: Combines code, pipelines, issues, and security.
- AWS deployment compatibility: Supports deployments into AWS environments.
Best For: Teams seeking tightly integrated CI/CD without managing multiple tools.
Jenkins is an open-source automation server for building highly customizable CI/CD pipelines. It prioritizes extensibility and full control over managed simplicity.
Key Features:
- Extensive plugin ecosystem: Integrates with nearly any tool or platform.
- Pipeline-as-code: Uses Jenkinsfiles for versioned pipeline workflows.
- Flexible execution environments: Runs on VMs, containers, or bare metal.
- Custom workflow support: Handles complex, non-standard pipeline logic.
Best For: Teams that need deep customization and complete control over CI/CD behavior.
21.GitHub Actions
Source
GitHub Actions provides CI/CD automation directly within GitHub repositories. By running workflows natively, it reduces the overhead of external integrations and tightly couples pipeline execution to GitHub events.
Key Features:
- Repository event triggers: Workflows run automatically on commits, pull requests, tags, and releases.
- Workflow-as-code execution: Pipelines are defined and versioned using YAML files.
- Reusable action ecosystem: Leverages both community and vendor-maintained actions.
- Flexible runner model: Supports GitHub-hosted runners or self-managed runners.
Best For: Teams already building on GitHub that want seamless, native CI/CD without maintaining a separate pipeline system.
22.Bitbucket Pipelines
Source
Bitbucket Pipelines is a CI/CD service embedded directly in Bitbucket repositories. It prioritizes simple, container-based pipelines and integrates smoothly with the Atlassian ecosystem.
Key Features:
- Repository-native configuration: Pipeline definitions reside alongside application code.
- Containerized pipeline execution: Jobs run inside Docker images defined per step.
- Branch-aware workflows: Supports branch-and environment-specific logic.
- Atlassian tooling alignment: Integrates naturally with Jira and Bitbucket projects.
Best For: Teams standardized on Bitbucket and Jira that want straightforward CI/CD without external tools.
CircleCI is a CI/CD platform optimized for fast, parallel pipeline execution, helping teams reduce feedback time and accelerate delivery.
Key Features:
- Parallel job execution: Distributes workloads automatically across multiple executors.
- Declarative pipeline configuration: Defines workflows using version-controlled configuration files.
- Multiple execution environments: Supports Docker, VM, and Kubernetes-based runners.
- Reusable pipeline components: Shares logic via CircleCI orbs.
Best For: Teams prioritizing fast CI feedback and high pipeline throughput.
Ansible is an agentless automation tool for configuration management and operational tasks. It executes procedural automation over SSH or APIs without requiring persistent agents.
Key Features:
- Agentless execution model: No agents are needed on managed systems.
- Playbook-driven automation: Uses YAML playbooks to define automation tasks.
- Idempotent behavior: Repeated runs converge systems to the same desired state.
- Broad automation scope: Automates servers, cloud resources, and network devices.
Best For: Teams automating configuration changes and operational workflows without managing agents.
Chef is a configuration management platform that enforces desired system states using a pull-based model. It continuously converges infrastructure to match declared policies.
Key Features:
- Policy-defined system state: Uses cookbooks and recipes to describe configurations.
- Agent-based convergence: Nodes reconcile themselves with the desired state regularly.
- Test-driven infrastructure support: Encourages validation before deployment.
- Fleet-scale consistency: Manages configurations across large server estates.
Best For: Teams operating long-lived infrastructure fleets that require strict configuration enforcement.
Puppet is a declarative configuration management platform designed for scale and compliance. It ensures the desired system state via continuous agent-based enforcement.
Key Features:
- Continuous drift remediation: Agents automatically correct configuration deviations.
- Centralized access controls: Manages who can modify infrastructure.
- Compliance visibility: Tracks configuration compliance across environments.
- Declarative configuration language: Defines desired state centrally.
Best For: Organizations managing regulated or compliance-sensitive infrastructure at scale.
Datadog is a full-stack observability platform that aggregates metrics, logs, and traces. It provides correlated visibility across application and infrastructure layers.
Key Features:
- Unified telemetry ingestion: Collects metrics, logs, and traces in one platform.
- Service-level observability: Connects application behavior with underlying infrastructure signals.
- Real-time alerting: Triggers notifications based on thresholds and patterns.
- Deep AWS integrations: Natively ingests telemetry from AWS services.
Best For: Teams running distributed systems that need centralized, correlated observability.
New Relic is an observability platform focused on application performance and distributed tracing. It emphasizes end-to-end visibility across services and user transactions.
Key Features:
- Application performance monitoring: Tracks latency, throughput, and error rates.
- Distributed request tracing: Follows requests across microservices.
- Unified telemetry platform: Ingests metrics, logs, and events.
- Query-based analysis: Uses NRQL for deep investigation of telemetry data.
Best For: Teams diagnosing application-level performance issues in complex service architectures.
29.Prometheus
Source
Prometheus is an open-source monitoring system built around metrics collection and time-series storage. Its pull-based model is ideal for dynamic cloud environments.
Key Features:
- Pull-based metrics collection: Scrapes metrics directly from instrumented targets.
- Powerful query language: Uses PromQL for time-series analysis.
- Dynamic service discovery: Automatically finds targets in cloud environments.
- Alerting integration: Works with Alertmanager for notifications.
Best For: Teams running Kubernetes or cloud-native systems that prefer open-source metrics monitoring.
Grafana is a visualization and alerting platform for metrics, logs, and traces. It helps teams convert telemetry data into shared, actionable dashboards.
Key Features:
- Multi-source data visualization: Connects to Prometheus, CloudWatch, and other backends.
- Customizable dashboards: Build role-specific and service-specific views.
- Alerting on visualized data: Triggers alerts based on dashboard queries.
- Observability correlation: Links metrics, logs, and traces visually.
Best For: Teams that need flexible dashboards combining data from multiple observability sources.
Here’s a quick comparison table:
Knowing the key tools available makes it easier to put together effective strategies for AWS DevOps optimization.
Also Read: Using Amazon ECS Spot, Savings Plan, and Reserved Instances to Optimize Costs
10 Key Strategies for AWS DevOps Optimization
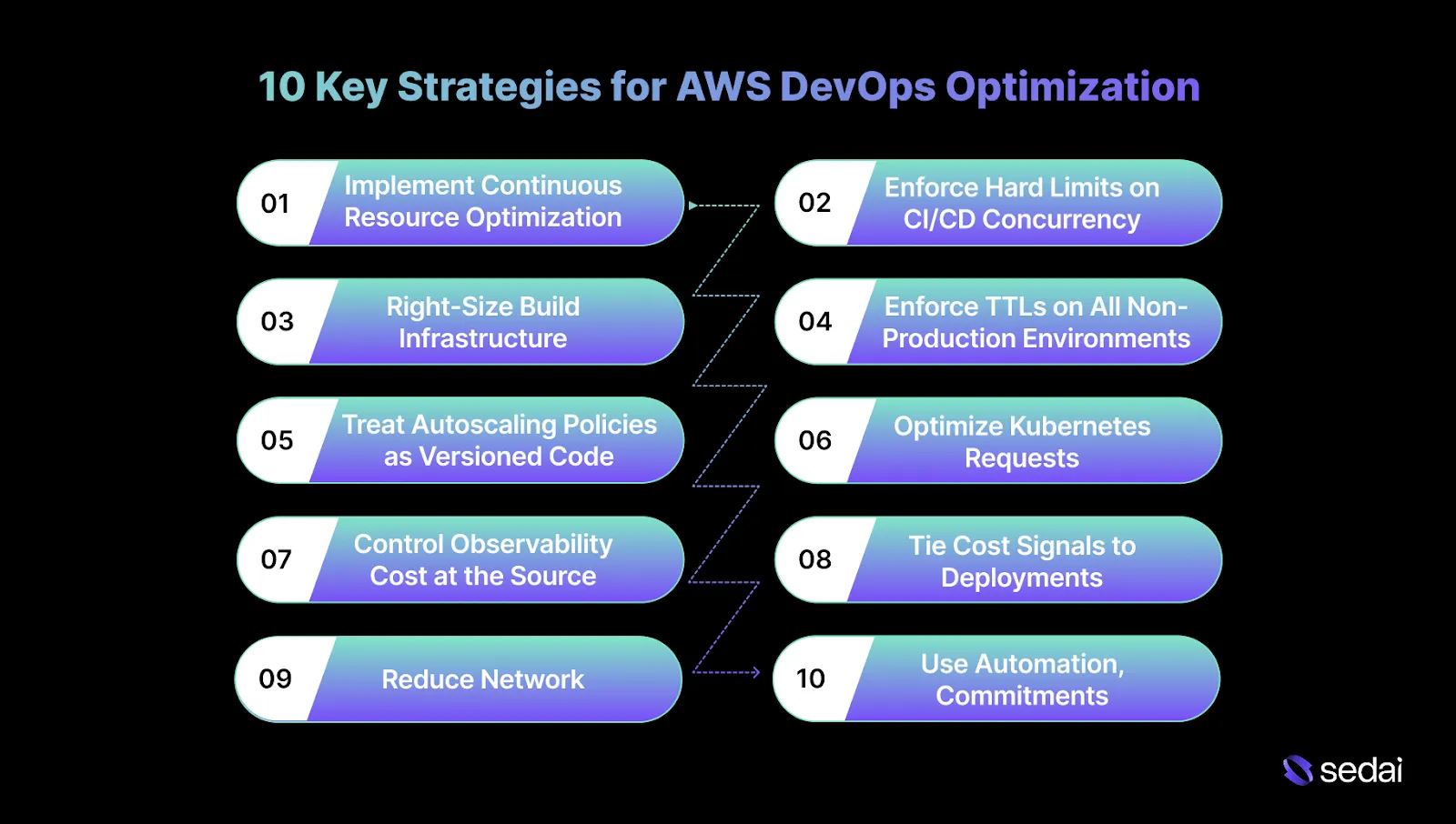
AWS DevOps optimization strategies become essential when pipelines, environments, and scaling policies change daily. These strategies focus on controlling how infrastructure responds to that change, keeping cost and efficiency predictable as systems change.
1.Implement Continuous Resource Optimization
- Detect sustained underutilization using AWS Compute Optimizer and service-level metrics across EC2, EKS, ECS, and Lambda.
- Apply automated rightsizing with guardrails that roll back on latency, error rate, or saturation regressions.
- Validate improvements in production using behavior-aware optimization tools.
2.Enforce Hard Limits on CI/CD Concurrency
- Set explicit per-repo and per-branch concurrency caps in CodeBuild, GitHub Actions, or self-hosted runners.
- Monitor queue depth to surface workflow inefficiencies earlier than build time alone.
- Gate changes using cost-per-build and duration trends.
3.Right-Size Build Infrastructure Based on Saturation
- Measure peak usage during the most resource-intensive build phases.
- Reduce capacity incrementally while validating build stability.
- Isolate heavyweight jobs instead of sizing all runners for worst-case workloads.
4.Enforce TTLs on All Non-Production Environments
- Attach TTLs at creation by requiring expiration metadata in Terraform, CloudFormation, or CDK.
- Destroy environments automatically on merge, inactivity, or TTL expiry.
- Block unowned stacks by preventing creation without ownership tags and expiration rules.
5.Treat Autoscaling Policies as Versioned Code
- Version scaling policies in Git and deploy changes through CI/CD.
- Test behavior under realistic traffic patterns.
- Define rollback criteria and revert on latency, error rate, or saturation regressions.
6.Optimize Kubernetes Requests Before Nodes
- Analyze long-term usage and base request changes on historical CPU and memory data.
- Reduce padding gradually while validating scheduling impact.
- Optimize node pools only after workloads declare realistic resource needs.
7.Control Observability Cost at the Source
- Set environment-based log levels and keep verbose logging out of production by default.
- Limit retention aggressively for non-critical logs and metrics.
- Eliminate low-signal, high-cardinality metrics that do not drive decisions.
8.Tie Cost Signals to Deployments
- Track cost per deploy by service and environment.
- Alert on deploy-linked cost spikes and correlate regressions with recent changes.
- Require rollback context for cost-impacting changes.
9.Reduce Network and Storage Waste Through Lifecycle Controls
- Audit network paths regularly, including NAT Gateway usage and cross-AZ traffic.
- Use CDNs deliberately by fronting user-facing services with CloudFront to reduce egress.
- Enforce storage lifecycle rules by applying S3 policies, pruning snapshots, and limiting artifact retention.
10.Use Automation, Commitments, and Security with Explicit Guardrails
- Commit after stabilization by using Savings Plans or Reserved Instances only for steady-state workloads.
- Restrict resource creation through least-privilege IAM to prevent shadow infrastructure.
- Bound automation tightly with defined scale limits, environment scopes, and approval paths for high-impact action
Must Read: AWS Lambda Concurrency Explained: Setup & Optimization
Final Thoughts
AWS DevOps optimization is effective only when it is embedded into how systems are designed, deployed, and operated.
As AWS environments scale, manual tuning struggles to keep pace with the rate of change. This is why many engineers are moving toward autonomous optimization.
By learning real workload behavior, assessing risk before every action, and continuously adjusting live infrastructure, platforms like Sedai help keep costs predictable while safeguarding performance and reliability. Stay in control of how your AWS environments change with every deployment.
Safely automate optimization, eliminate waste you already recognize, and preserve reliability as your systems scale.
FAQs
Q1. How do you measure whether AWS DevOps optimization changes actually worked?
A1. You measure success by comparing clear before-and-after baselines for cost, latency, error rates, and resource saturation tied to a specific deploy or scaling change. If costs decrease without negatively affecting p95 latency, error budgets, or availability, the optimization can be effective.
Q2. Can AWS DevOps optimization interfere with incident response?
A2. Yes, if automation continues to act without awareness of an active incident or human intervention. Optimization should be paused or tightly constrained during incidents, and every action must be reversible and fully auditable.
Q3. How do you prevent AWS DevOps optimization tools from conflicting with each other?
A3. Conflicts are avoided by defining clear ownership boundaries across CI/CD, IaC, observability, and runtime optimization tools. Each tool should operate only within its intended scope, with optimization restricted to bounded, runtime-safe actions.
Q4. Does AWS DevOps optimization still matter for low-change or stable workloads?
A4. Yes, because even stable workloads accumulate waste over time through drift, overprovisioning, and unused resources. Optimization helps validate old assumptions and gradually remove excess capacity as traffic patterns shift.
Q5. When should engineers stop optimizing and accept higher AWS costs?
A5. You stop optimizing when further cost reduction would compromise redundancy, recovery time, or failure isolation. At that point, a higher cost represents a deliberate reliability choice.











